Understanding Git
Git is a version control system (VCS) enabling collaborative work on source code. It is considered the standard that every developer should know. It is also crucial to understand how Git is used for, e.g., project management since it is fundamental to the way software is developed collaboratively. If you are unfamiliar with Git, there are many online tutorials which will satisfy your information needs to an arbitrary depth (see, for instance, here or here, which have been used while writing this tutorial). In this tutorial, only the most important Git facts and commands are explained in a condensed fashion. For some of the subsequent statements there exist some intentional inaccuracies or exceptions. However, for this course, the given information combined with some own research should be enough for you to be productive with Git.
The basic structures in Git
Broadly speaking, Git enables developers to clone, that means “download”, code from a remote repository into the developer’s local repository positioned on the developing machine. The developer then can apply changes to the code which are then pushed back to the remote repository. Prominent hosts of remote repositories include GitHub and GitLab. In this course, you are provided with a repository on ZIV GitLab.
Most often, the remote repository consists of different branches. These branches each represent the code base with different changes applied to it. The master (sometimes also called main) branch is the default branch which is created during the initialization of a new repository. The master branch can be thought of as the history of production-ready versions of the code. For new features, development takes place on development, e.g., feature branches. If, for instance, a new functionality is added to the code base, a new feature branch is created. While developing this feature one does not touch the code base on the master branch. It might even be sensible to have further subbranches of a feature branch to develop subfeatures. The master branch should never contain an instable version of the source code. (For instance, there never should be security concerns due to some halfway-done feature.) Once the feature is stable and adequately tested, it is merged into the master branch, that means, the feature is added to the stable code base. Branches can also be created for other purposes such as non-features like refactoring code.
(Opinionated) most important commands
While this has been an abstract discussion on what Git is used for, this section will explain some basic commands and their meaning. All commands have various additional arguments which you can specify but which are omitted at this point. If you are in a specific situation and the given commands are insufficient, you can consult the documentation (for example here).
Broadly speaking, we differentiate between the file system, the staging area, the local repository, and the remote repository. The Git commands, as summarized in the image below, are mostly responsible for transferring file changes between these different locations. The code on the remote repository can be accessed by different developers. The local repository, the staging area, and the working space, i.e., the file system, are all located on the developer’s machine.
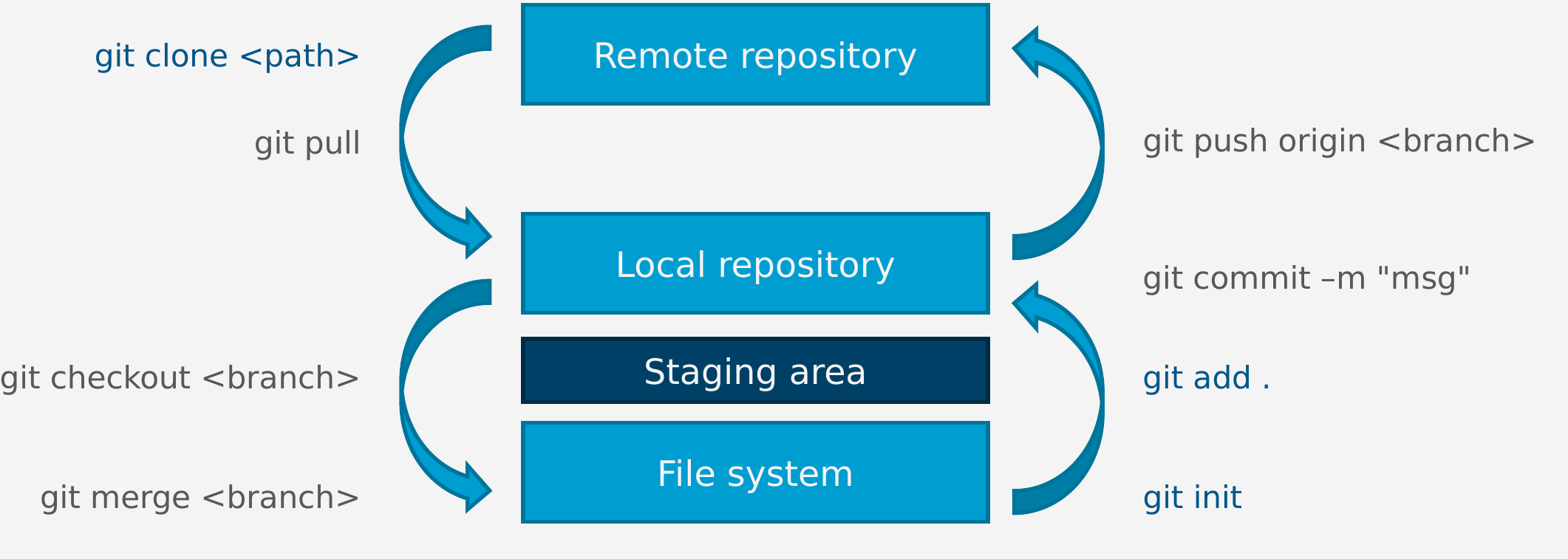
The transferal of files can be best described by the different Git commands. They are executed using a console at the location where your project is located. You can also execute these commands via the GUI of the Eclipse Git integration (see Eclipse Git integration). However, for understanding the Eclipse Git integration, it is strongly advised to read about the functionality of the subsequent commands.
In the following, in-code words written in cursive represent context-specific text. For instance existing_feature_branch represents the name of an existing branch.
git initinitializes a new repository at the given position. You do not have to do this if you usegit cloneon an existing repository.git cloneclones the given repository. You will have a local copy of all files in the repository. Example:git clone https://github.com/wwu-pi/adder-application.git checkoutswitches between existing branches. If you currently have the master branch checked out (which is the default), and you check out a feature branch, the files in your local working directory (the files on your development machine) will change to the state of the feature branch. Example:git checkout existing_feature_branch. New branches in the remote repository must first befetched (see below).git checkout -bcreates and checks out a new feature branch. If you currently have the master branch checked out, and you want to work on a new feature, you can create a new branch for this and immediately switch to this new branch. Your files will be the same as on the previous branch, butpush-commands (see below) will target the new branch. Example:git checkout -b new_feature_branch.git addadds the current version, i.e., the current snapshot of the chosen files to the staging area. Files that are not added to the staging area cannot becommitted and laterpushed (see below). Explicitly callinggit addsometimes is not necessary (seegit commit). Example:git add MissingClass.javagit commit -m commit messageapplies the changes in the staged files to your local repository. All invocations ofgit addare bundled in one subsequent commit. The changes are commented with a message and show up in the commit history of the repository (as an example, see here). This makes it easier to track down erroneous changes. As a shortcut, you can “skip” the explicitgit add-call by executinggit commit -am commit message. This should only be done if you want to include all tracked files into the commit. Each file in the working directory is tracked or untracked. After cloning, all cloned files are tracked. If you wish to untrack a file, you must do so explicitly. You can also “skip” the explicitgit add-call by specifying the files that should be commited in the commit call:git commit file0 file1 ... -m commit message. Note that this only works if you already track the files you want to commit. If this is not the case,addthem first.git diffshows the difference between the two Git data sources. Example:git diffwill show the difference between your current, uncommitted local changes and your committed changes.git pushapplies the changes which reside in your local repository to the remote repository. If you switched to a feature branch and have committed changes, the changes are only visible for you. After executinggit pushthe changes are “uploaded” to the remote repository so that others might “download” them. If you wish to push a new branch, which does not yet exist on the remote repository, usegit push -u origin new_branch, where new_branch is the name of the branch you want to push.-
git pull“downloads” the latest code base from the currently checked out branch. You should have committed all of your changes before attempting to pull changes from the remote repository. If someone changed the remote code and these changes are not yet in your code,git pullwill try to merge the two versions automatically. (Under the hood,git fetchandgit mergeare executed bygit pull.) If this does not succeed, a merge conflict is present which must be resolved manually. For this, the corresponding files must be edited. The merge conflict in the file is indicated by<<<<<<< HEADsome code=======some other code>>>>>>> other_versionThe portion of code between
<<<<<<< HEADand=======indicates one version of the two versions which caused a merge conflict. On the other hand, code between=======and>>>>>>> other_versionindicates the other version involved in the merge conflict. You have to manually decide on which changes are the correct ones, delete the indicators, and commit as well as push the changes. To commit a merge conflict-resolution, commit the conflicting files usinggit commit -i file0 file1 ... -m commit message. To avoid merge conflicts it is useful to work on disjoint portions of the source code.Another scenario where it makes sense to pull changes is to add a feature to the master branch. If you currently have checked out the feature branch, you might want to execute
git checkout masterfollowed bygit pull origin feature_branch. You then will have to push the pulled changes to the remote repository. git fetchretrieves the most recent metadata from the specified repository. If, for instance, a colleague created and pushed a new branch which you too want to work on, you first might need to fetch the metainformation to see that this branch is available before executinggit checkout new_feature_branch.-
To push an existing repository to a new repository, a sequence of commands can be executed. First, clone the repository via
git clone existing repository url. Then, rename the remote origin to avoid conflicts viagit remote rename origin some other name. As the third step, add the new remote origin viagit remote add origin repository-url.git. Lastly, push the branches to the new repository viagit push -u origin --all. Example:git clone https://github.com/wwu-pi/adder-applicationcd adder-applicationgit remote rename origin old-origingit remote add origin https://zivgitlab.uni-muenster.de/yourUserName/my-adder-applicationgit push -u origin --all.
The .gitignore file
In a repository there usually is a .gitignore file. In the .gitignore-file you can specify patterns and specific names
which should not be managed by Git. You can see an exemplary .gitignore-file here.
It usually only makes sense to exclude files that are specific for the developer at hand, such as specific configurations. If, for example, you have
a personal password or API key for a service which is assigned to you, it might make sense to not include this personal information in the repository and use
.gitignore here. Specifying a file in the .gitignore-file is not the same as untracking it. You must explicitly untrack a file if you added a git-ignore rule.
git ignore file can be used to explicitly ignore a file. git rm --cached file can be used to untrack it.
The framework we are using precreates a .gitignore-file which you can adjust.
Eclipse Git integration
Eclipse offers a Git integration. This Git integration is available per default in the IDE and can be used instead of using a console to execute git-commands. When right-clicking a file in the package explorer, select “Team” to open the options of the Git integration. For instance, you can select files which you want to commit: Upon clicking “Commit…” you can stage files and also review which changes you are about to commit. To check what you changed right-click a file in the “Git Staging” view (which opens automatically when clicking “Commit…”). Then, select “Compare with Working Tree”. Via “Team” > “Repository” you can push commits to the current branch (“Push to origin”), fetch metadata (“fetch from origin”) and pull changes. Via “Team” > “Repository” > “Switch to” you can checkout known branches or create new ones.